

Development of a Web Service for Creating Digital Human Replicas
AI-REPLICA (also known as Afterlife.ai / Timeless.ai) is an innovative web service designed to create highly realistic digital human replicas (AI-Replicas).
The product is built on an AI chatbot that combines deep profile-based personalization with advanced RAG (Retrieval-Augmented Generation) technology.
The project was initiated by a private individual in Australia through our partner. For our team, this was the first experience working with this client, which required us to build all processes from scratch, starting with a deep dive into a very personal and sensitive product concept.

Task
The main task set by the client was very ambitious and extended beyond standard chatbot development. The goal was to create a “digital personality imprint” — a replica of a specific person in the form of a chatbot that would not only answer questions but also perfectly replicate this person’s communication style, use facts from their biography, and demonstrate their key personality traits.
The ultimate goal of the system, as envisioned by the client, was to enable relatives and loved ones to continue “communicating” with the person after their passing, preserving their digital memory.
To put this concept in terms of technical and business tasks, the project needed to solve the following key objectives:
- Provide deeply personalized AI conversations: Ensure that the AI goes beyond general responses, delivering conversations that are consistent, natural, and based on a unique personality profile.
- Implement seamless onboarding (Wizard): Develop an intuitive multi-step survey form (wizard) to collect specific data about the user. This data — ranging from favorite books and biographical facts to political views and communication style — would serve as the foundation for the AI's “personality.”
- Create a reliable contextual retrieval mechanism (RAG): Build an architecture that allows the AI to dynamically extract relevant facts from the created profile in real time, generating appropriate responses during conversations.
Initially, the target audience appeared narrow: elderly individuals and patients with serious illnesses who might wish to leave behind this type of digital footprint. However, upon further analysis, it became clear that the potential audience was much broader, encompassing any end user interested in creating their own personalized digital twin for communication for various reasons.

Solution
To accomplish such a complex task, we proposed a modern and modular architecture.
The key element of the solution was a sophisticated RAG (Retrieval-Augmented Generation) flow. Instead of simply sending the user’s query to an LLM (as simple chatbots do), our system performs a multi-step process:
- It analyzes the user's query.
- Instantly performs a semantic search of the vector database (Qdrant) where all the facts about the user and their personality traits are stored.
- Finds the most relevant pieces of information (e.g., “fact about childhood,” “opinion about music”).
- “Augments” the user's initial query with this information.
- Sends this enriched, highly contextual prompt to the LLM (OpenAI) for response generation.
This approach ensures that the AI “remembers” who it is and responds according to its “personality.”
Development Process
The project was planned as an intensive MVP (Minimum Viable Product) development with very tight deadlines.
- Time frame: 1 month (divided into 4 one-week sprints).
- Estimated labor costs (MVP): 352 to 473 total hours.
The process was structured to be as parallel as possible to meet the deadlines:
- Analytics, Design, and Prototyping (Parallel):
- Analytics: The business analyst developed the requirements for the website and backend, describing the logic of the wizard, API, and RAG flows.
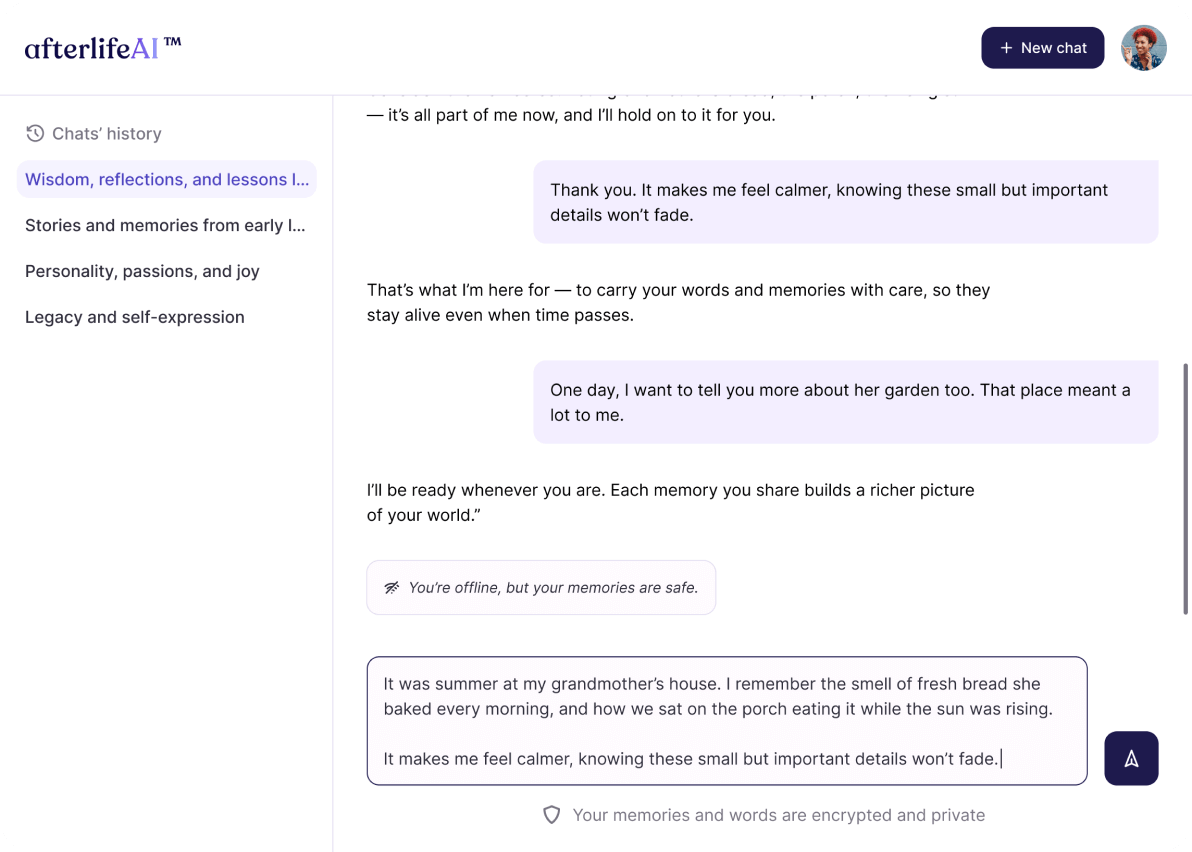
- Design: The designer worked in Figma to create the chat interface, multi-step form screens, and a scenario for the user’s initial interaction with the system.
- Prototyping: We approached this project unconventionally. Since evaluating the result (“does it seem human or not”) was extremely subjective, our first step was to create a quick prototype using the low-code platform n8n. This allowed us to test the concept of AI agents, experiment with logic, and focus on achieving the best quality of AI responses before starting to write complex production code, all quickly and at minimal cost.
- Development (Main stage):
- Frontend (ReactJS): Development of the chat UI and survey form.
- Backend API (Ktor): Development of API for authentication, profile management (Wizard), and chat message processing.
- Backend AI (Ktor/Koog/Qdrant): The hardest part. Integration with OpenAI, implementation of RAG flows, configuration of the PII filter (for personal data protection), and configuration of the entire database stack (Postgres, Redis, Qdrant).
- QA and PM (End-to-end processes): Testing and project management continued throughout all of the sprints.
Team composition: The project was carried out by a compact and highly efficient cross-functional team:
- 1 Project Manager
- 1 Analyst
- 1 Designer
- 2 Backend Developers
- 1 Frontend Developer
- 1 QA Specialist
The Hardest Part
During development, we encountered three main challenges that required non-trivial engineering solutions.
- Complex Personalization (RAG-Flow): This was the main challenge. It was not enough to simply “plug in” ChatGPT. We needed to ensure that the AI twin provided consistent and personalized responses based on dozens and hundreds of facts from the profile. How could we get the AI to “remember” the right fact at the right moment? The hardest part was fine-tuning the system prompt and the logic for retrieving additional context (facts) from the Qdrant vector database.
- Data Privacy (PII): The user profile had to contain a large amount of personally identifiable information (PII), such as names, dates, personal stories, opinions, etc. At the same time, the architecture required the use of an external API (OpenAI). This created a critical conflict: how could we utilize this data for personalization without explicitly transferring it to an external API? Ensuring the confidentiality of PII became our top priority.
- Performance (NFR): The effect of “live” communication disappears if the chatbot takes 10–15 seconds to formulate an answer. We established a strict non-functional requirement (NFR): the average chatbot response time should not exceed 5 seconds. This was a very aggressive goal, given the complexity of our RAG flow: within those 5 seconds, the system had to receive a message, query Redis for history, query Qdrant for relevant facts, construct a complex prompt, send it to OpenAI, receive a response, and return it to the user.
How we solved these tasks
Our team developed and implemented a specific technical solution for each of these three challenges.
- Solution for RAG (Personalization): To achieve high-quality responses, we implemented dynamic backend logic (Ktor + Koog).
- Background: Initially we considered simply transferring the entire user profile to OpenAI, but quickly realized that this was both inefficient (due to token limitations) and irrelevant (the AI would be overwhelmed by unnecessary information).
- Solution: We implemented a dynamic “Top-K” search. When a user sent a message, the backend first performed a semantic query to Qdrant to find the 4–6 most relevant facts (chunks) from the profile.
- These 4–6 facts were then formatted into a special context block and dynamically “pasted” into the final prompt for OpenAI.
- Simultaneously, we engaged in methodical prompt engineering, refining the main system prompt to teach the AI to correctly interpret and use this additional context.
- Solution for PII (Privacy): To protect PII, we implemented a PII filter and a personal data tokenization mechanism.
- Background: Simple encryption was not a viable option, since OpenAI needed to understand the meaning of the data to generate vectors (embeddings).
- Solution: We developed a PII filter on the backend. When preparing data for the vector database (before sending it to the OpenAI Embeddings API), this filter would detect and replace all personal information with special tokens. For example, “My dog's name is [DOG_NAME_1]” or “I live in [USER_CITY_1]”.
- This way, the external OpenAI API never saw any real names or addresses. It only dealt with impersonal tokens, which completely eliminated the risk of PII leakage. At the same time, our internal PostgreSQL database stored the matches between these tokens and the real data.
- Solution for Performance (NFR): To stay under 5 seconds, we had to optimize every step. The biggest “devourer” of time and tokens was the transfer of the entire chat history.
- Background: The “naive” approach involved sending the entire dialog history to OpenAI with each new message. This quickly exceeded the token limit and slowed down response times.
- Solution: We used Redis to manage sessions and store recent chat history (memory). Instead of sending the entire history, we only sent a “sliding window” of the latest messages. This allowed us to maintain the continuity of the conversation (the AI remembered what was discussed two minutes ago) while drastically reducing the number of tokens transmitted and optimizing the API load. This solution directly improved response times and reduced the cost of each query.
Technology Stack
Frontend
 ReactJS
ReactJS Flowbite (Tailwind CSS) UI-kit
Flowbite (Tailwind CSS) UI-kitBackend
 Ktor (Kotlin)
Ktor (Kotlin) Koog by JetBrains
Koog by JetBrainsDatabases
 PostgreSQL
PostgreSQL Redis
Redis Qdrant
QdrantAI Services
 OpenAI API
OpenAI APIOther
 Stripe для интеграции платежей
Stripe для интеграции платежей Digital Ocean (хостинг)
Digital Ocean (хостинг) n8n
n8nResults
The project was planned as a quick MVP with a one-month deadline. Unfortunately, due to circumstances beyond the control of the development team, the project was not completed in full.
However, we managed to conduct an in-depth analysis, create a complete product design, and develop and test the architecture and key complex mechanics, including the RAG flow and PII filter.
We do not have information about the subsequent fate of the project. The team handed over all completed work to the customer:
- Complete documentation and analytical data.
- Finished design layouts in Figma.
- Project folder with documentation.
- Codebase with the implemented architecture
Although this product did not see release, this case proved to be a valuable experience for our team in developing complex, high-performance, and secure AI systems using RAG architecture. We successfully solved non-trivial problems related to PII protection and performance optimization when working with LLMs.

